Crawling, Indexing, Ranking: ce inseamna Crawl Budget pentru Google?

Obiectivul corect setat al unei campanii SEO este cresterea vizibilitatii site-ului in rezultatele organice Google pentru termeni de tip non-brand relevanti. Acest lucru este insa o consecinta directa a imbunatatirii pozitiilor pe care site-ul le ocupa in SERPs pentru respectivele cautari, adica este o chestiune de Ranking.
Pana a discuta insa despre Rnking exista alte doua etape, peste care se trece de multe ori cu prea mare usurinta, atat de proprietarii de site-uri, cat si de anumiti furnizori de servicii SEO. Aceste doua etape sunt Crawling si Indexing:

Practic, in partea de Crawling, Google acceseaza paginile unui site, in faza de Indexing le intelege continutul, iar in Ranking le ordoneaza conform algoritmului sau, pentru a le afisa in pagina cu rezultate. Nu putem asadar sa discutam despre pozitii bune in Google (Ranking), fara a trata cele doua faza premergatoare.
In cadrul acestui articol ne vom ocupa in detaliu despre partea de Crawling, atat pentru faptul ca este prima faza in proces cat si pentru ca Google a publicat recent un material detaliat in care clarifica anumite concepte si demoleaza o serie de mituri destul de raspandite in industrie. In viitor, vom publica pe blogul DWF un articol dedicat fazei de Indexing.
Definirea unor concepte esentiale in Crawling, confrm Google:
#Google Crawl rate limit
Prioritatea principala a GoogleBot este sa identifice URL-urile de pe Internet, astfel incat acestea sa poata fi preluate in indexul Google si ulterior ordonate in functie de relevanta, pentru fiecare cautare in parte. Practic, GoogleBot acceseaza fiecare website si navigheaza apoi pe el, „din link in link”, incercand insa ca in acelasi timp sa nu degradeze experienta de utilizare a site-ului pe care o au vizitatorii acestuia, printr-un consum prea mare de resurse.
Pentru a se asigura de acest lucru, inginerii Google folosesc notiunea de „crawl rate limit”, adica un numar maxim de conexiuni simultane pe care GoogleBot le poate deschide cu un website in timpul procesului de crawling, precum si timpul pe care acesta sa-l astepte intre solicitarea de pagini de la server. Aceasta limita poate varia in functie de mai multi factori, printre care Google mentioneaza:
- Crawl health: daca site-ul raspunde rapid la solicitarile Google pentru un anumit timp, inseamna ca serverul poate suporta un ritm mai accelerat de crawling, prin mai multe conexiuni deschise simultan.
- Daca site-ul incepe sa raspuna greu (vezi raportul Crawl > Crawl Stats > Time spent downloading a page), sau genereaza erori de server (raportul Crawl > Crawl Errors), rata de crawling se reduce.
- Limitari din Search Console: proprietarii de site-uri pot indica o anumita preferinta pentru ritmul de indexare folosind optiunea „Crawl rate” din Google Search Console.

De mentionat ca setarea unui limite ridicate aici nu inseamna automat ca GoogleBot se va conforma, ci doar ca din partea proprietarului nu exista o limitare in acest sens. De asemenea, instructiunea „crawl-delay” din fisierul robots.txt nu este procesata de GoogleBot.
In esenta, daca site-ul nu are o problema de resurse, adica ruleaza pe un server suficient de puternic, este bine ca GoogleBot sa cat mai activ pe site, adica sa crawl-eze un numar cat mai mare de pagini zilnic.
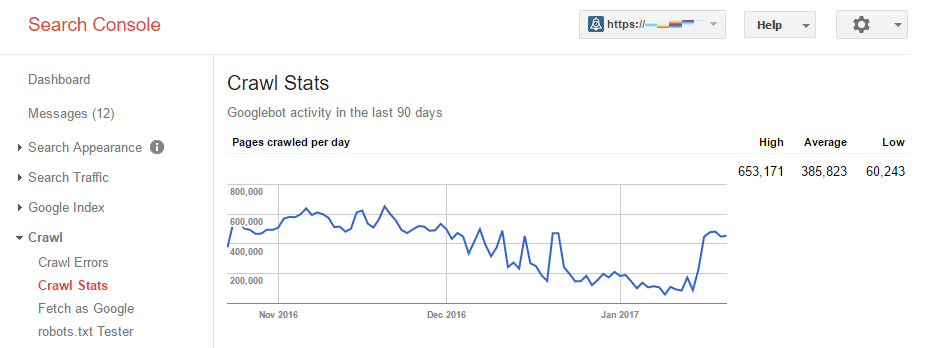
In Google Search Console putem vizualiza rata cu cate GoogleBot indexeaza un site. Aceasta informatie este disponibila in raportul Crawl > Crawl Stats (imaginea de mai jos). Numarul de pagini accesate de GoogleBot in fiecare zi este un bun indicatoral eficientei modului in care este structurat un site, din punct de vedere SEO.
#Google Crawl demand
Chiar daca limita de crawling nu este atinsa, GoogleBot poate avea o activitate mai scazuta, in conditiile in care nu exista o nevoie de craling din partea motorului de Indexare Google (algoritmul responsabil pentru a doua faza din procesul Craling – Indexing – Ranking). Exista doi factori principali care pot influenta rata de Crawl demand:
- Popularitatea unui URL: adresele care beneficiaza de un grad ridicat de popularitate tind sa fie trimise mai des catre motorul de crawling, astfel incat continutul lor sa fie actualizat cat mai frecvent in indexul Google.
- Vechimea (data ultimului crawl): sistemul incearca sa mentina informatiile cat mai proaspete in Index, in general.
Cei doi factori sunt comunicati de Google, in aceasta forma. Este interesant de observat ca in cazul popularitatii, se face referire la URL, nu la domeniu. In al doile rand, Google nu precizeaza in ce consta sau cum cuanifica aceasta popularitate (linkuri, mentiuni, semnale sociale).
In plus, un factor care poate sa determine o crestere a acestei rate consta in modificari majore la nivel de website, precum migrarea catre o platforma noua, restructurarea masiva a site-ului etc.
Tinand cont de crawl rate limit si de crawl demand, Google defineste Crawl Budget drept „numarul de URL-uri pe care Google poate si doreste sa le crawleze” de la un website.
#Factori care influenteaza Google Crawl Budget
Conform Google, existenta unui numar mare de URL-uri cu valoare scazuta a continutului poate afecta in mod negativ rata de crawling si indexare a unui site. Cele mia frecvent intalnite pagini care genereaza astfel de probleme, conform datelor Google, sunt urmatoarele:
- Navigarea fatetata sau filtrele incorect implementate. Pentru mai multe detalii, recomandam Ghidul DWF dedicat acestui subiect, precum si aceasta postare Google din 2014, in care sunt explicate greselile, dar sunt formulate si recomandari concrete de realizare a acestui element.
- Utilizarea incorecta a parametrilor de sesiune in URL-uri. Pentru mai multe detalii, recomandam materialul DWF despre canonicalizarea linkurilor.
- Existenta de continut duplicat in site, fie de natura tehnica (adica obtinut prin acceseibilitatea unui element de continut la mai multe URL-uri necanonice), fie efectiva (ex: aceeasi descriere la mai multe produse, paragrafe semnificative de text repetate pe toate paginile etc).
- Generarea unui numar mare de erori 404 sau erori de crawling (vezi in Google Search Console). Acest lucru poate indica faptul ca serverul pe care este gazduit site-ul nu poate face fata unei rate mai mari de crawling, precum si ca nu este capabil sa ofere o experienta buna vizitatorilor.
- Pagini a caror securitate a fost compromisa (sunt „virusate”). Google a anuntat recent ca SEO este unul dintre principalele motive pentru care site-urile sunt atacate.
- Generarea de „infinit pages”, adica producerea dinamica a unui numar nelimitat de pagini, ca de exemplu intr-un calendar in care avem un link spre „luna urmatoare”. Google ofera mai multe detalii despre acest tip de situatie si exemple de evitat, intr-un articol dedicat.
- Continut de slaba calitate sau de tip SPAM.
Google avertizeaza ca acest tip de pagini consuma in mod nejustificat resurse (atat pentru GoogleBot cat si pentru proprietarul de site), in detrimentul paginilor care ar avea un continut suficient de important pentru indexare si ranking. Mesajul este unul de responsabilizare a webmasterilor in vederea crearii conditiilor favorabile GoogleBot sa acceseze cu prioritate continutul important.
Pentru a simula modul in care GoogleBot acceseaza un site, folosim in cadrul DWF mai multe instrumente SEO premium de crawling, precum ScreamingFrog sau DeepCrawl. Acestea ne permit sa masuram rapid impactul pe care il au anumite modificari de structura si impactul lor SEO, fara sa asteptam un crawl si o indexare completa din partea Google. De asemenea, permit studierea oricarui site de pe Internet, astfel incat sa putem observa elementele comune pe care le au la nivel de structura interna domeniile cu cea mai buna vizibilitate SEO, pe o nisa anume.



















